


Jak powstali pierwsi inteligentni rywale w grach komputerowych.
Sztuczna inteligencja w dzisiejszych czasach otacza nas z każdej strony. Często nawet nie zdajemy sobie sprawy z tego, jak często z niej korzystamy. Wpisujesz frazę w wyszukiwarce, a komputer podpowiada Ci lepsze hasło? Piszesz SMSa, kiedy komórka kończy za Ciebie słowa i proponuje kolejne? W każdym z tych wypadków mamy do czynienia ze sztuczną inteligencją. Obecnie nawet pralki czy zmywarki dysponują systemami, które potrafią inteligentnie dobierać ilość wody i jej temperaturę, żeby zoptymalizować proces mycia.
Jednak nas szczególnie interesuje sztuczna inteligencja w grach komputerowych. Do dziś za największe osiągnięcie w tej dziedzinie uważa się komandosów z Half-Life oraz przeciwników w F.E.A.R. Jednak jak praktycznie każda rzecz na świecie, sztuczna inteligencja, gdzieś musiała się zacząć.
Pierwsze komputerowe mózgi
Pierwszy był Alan Turing w 1951 roku, którego większość informatyków będzie kojarzyła z maszyną Turinga. Jednak wiąże się z nim również pojęcie testu Turinga. Test bazował na prostej grze, gdzie sędzia rozmawia z dwoma osobami, zadając im pytania. Na podstawie pytań, ma określić płeć osób. W wersji Turinga, sędzia rozmawia z osobą i maszyną w języku naturalnym (czyli języku zrozumiałym dla ludzi, takim jakim posługujemy się na co dzień). Maszyna zdaje test, kiedy sędzia nie potrafi określić, który z rozmówców miałby być maszyną. Test ogólnie był dość kontrowersyjny i wielu badaczy nie traktowało go poważnie.

Źródło zdjęcia: http://airesearch.com/
W roku 1952 do akcji wkroczył Arthur Samuel. Pracownik IBM opracował swój samo uczący się algorytm gry w warcaby. Jego algorytm nie sprawdzał każdego możliwego posunięcia. Samuel opracował funkcję oceniającą szansę na zwycięstwo bazując na kilku zmiennych, takich jak pozycja pionka, liczba pionków po obu stronach etc. Sztuczna inteligencja starała się wykonywać takie posunięcia, aby optymalizować wartość funkcji. W 1954 roku, sztuczna inteligencja pokonała 4 najlepszego gracza USA w warcaby.
Do tej pory wymieniliśmy już dwóch pionierów w dziedzinie sztucznej inteligencji, jednak do roku 1956 jeszcze nikt nie operował terminem “Sztuczna Inteligencja”. Opracował go John McCarthy na konferencji w Dartmouth. Dokładniej był to angielski termin “Artificial Intelligence”. McCarthy zaproponował również język LISP, oraz był nagrodzony nagrodą Turinga za wkład w rozwój SI.

Źródło zdjęcia: https://www.chess.com/
Kolejnym ważnym krokiem w rozwoju inteligencji komputerowej, był rok 1967, w którym Richard Greenblatt stworzył swój program MacHack. Program powstawał na MIT i został pierwszym programem komputerowym, który brał udział w turniejach szachowych, jest również pierwszym oprogramowaniem, które pokonało żywego człowieka w pojedynku szachowym. Ciekawostką jest, że MacHack został honorowym członkiem Massachusetts State Chess Association, oraz w swoim najlepszym okresie był 1243 w rankingu szachowym.
Od tego czasu, rozwój sztucznej inteligencji w grach nieco przystanął. Dostępny sprzęt nie był zbyt szybki. Właśnie te ograniczenia techniczne sprawiły, że rozwój inteligentnych przeciwników na trochę przystanął. Pojawiały się co prawda gry wykorzystujące sztuczną inteligencję, jednak była ona banalnie prosta i do bólu przewidywalna.
Lata 90′ i pierwsze gry, które kojarzymy
Na kolejne istotne wydarzenie w zakresie rozwoju sztucznej inteligencji w grach komputerowych czekaliśmy do roku 1994 i gry Warcraft. Studio Blizzard pokusiło się na zastosowanie zaawansowanych algorytmów wyszukiwania ścieżki. W przypadku gry RTS, gdzie na raz wyświetlanych jest wiele jednostek, był to śmiały ruch, który okazał się ogromnym sukcesem. Agenci potrafili przemieszczać teren, omijając przeszkody i siebie wzajemnie. Już wtedy same algorytmy wyszukiwania ścieżki nie były niczym nadzwyczajnym. To co robiło tutaj wrażenie, to fakt jak wiele jednostek na raz potrafiło korzystać z tej możliwości.

Źródło zdjęcia: http://www.myabandonware.com/
W roku 1996 ponownie wracamy do gry w szachy. Na świecie głośno zrobiło się z powodu komputera Deep Blue stworzonego przez IBM. Maszyna siadła do partii szachów z ówczesnym mistrzem świata Garri Kasparowem. W pierwszym starciu komputer wygrał jednokrotnie, ale później przegrał 3 partię i 2 zremisował, przez co ogólnie skończyło się 4:2 dla Rosjanina. Po roku dodatkowych prac nad systemem, doszło do rewanżu. Tym razem maszyna wygrała 3.5 do 2.5.
Pierwszą grą, której inteligencje chwalono w całym świecie growym był wydany w 1998 roku przez Valve Half-Life. Nie stosował on żadnych wybitnych technik, jednak wprowadził inteligencję na nowym poziom. Jednym z wrogów, z którymi przyszło się mierzyć, byli komandosi. Tym co ich wyróżniało na tle innych przeciwników, był fakt, że potrafili ze sobą współpracować, wzajemnie się osłaniać, oskrzydlać gracza etc.

Źródło zdjęcia: http://www.tombraiderforums.com/
W tym samym roku pojawiała się również gra Thief wyprodukowana przez Looking Glass Studios. Developerzy skupili się tutaj na nieco innym aspekcie sztucznej inteligencji, jakimi są sensory. Sztuczna inteligencja nie potrafiąca odebrać bodźców ze środowiska jest bezwartościowa. W Thief strażnicy reagowali na dźwięki oraz światło.
Następny ważny krok nastąpił dość szybko, bo już w 1999 roku, za sprawą studia Digital Extremes, które zaprezentowało wtedy Unreal Tournament. Kluczowym elementem były tutaj boty, które potrafiły uczyć się od gracza. Jest to mechanizm stosowany aż do dziś w wielu grach multiplayerowych, gdzie mamy do czynienia z botami. Gra podpatruje sposób gry żywych graczy i stara się stosować podobne schematy poruszania się, czy dobre miejsca na kryjówki.
Sztuczna inteligencja po milenium
Kolejny śmiały krok w rozwoju SI nastąpił w roku 2000, a dokładniej w grze Colin McRae Rally 2.0, spod klawiatury Codemasters. Była to pierwsza gra, wykorzystująca sieć neuronową. Gra zbierała dane na podstawie sposobu jazdy gracza. SI opierało się na dwóch danych – linii jazdy oraz modelu jazdy. Pierwsza z danych to linia optymalnego toru jazdy, druga określana była przez szybkość, rodzaj nawierzchni etc. Wykorzystując dane o modelu jazdy, komputer starał się jak najbardziej trzymać linii jazdy. Dodając do tego wiedzę zebraną od gracza, SI mogło stawać się coraz lepszym kierowcą.
Również w 2000 roku pojawił się hit studia Maxis, a mianowcie The Sims. Pierwszy raz wprowadzono system potrzeb – gdzie nasza postać odczuwała głód, potrzebę umycia się czy skorzystania z toalety. Mało tego, agenci potrafili nawiązywać relację. Stworzono też ciekawy system, gdzie wykorzystano tak zwane inteligentne obiekty. Tzn. postać jako taka nie potrafiła używać różnych przedmiotów. To przedmiot informował naszego simsa, jak powinien zostać użyty. Później z podobnego rozwiązania skorzysta ekipa Monolith pracując nad AI do gry F.E.A.R.

Źródło zdjęcia: http://www.macworld.com/
Rok później na rynku pojawia się Black & White od studia LionHead Studios. Programiści postanowili stworzyć bardzo ciekawy projekt, jakim był chowaniec. Zwierzątko, które uczyło się, jak powinno się zachowywać. Jego rozwój opierał się na “wzmocnieniu”. Czyli mogliśmy go chwalić za dobre zachowanie oraz karać za złe. Dobrze wyszkolony chowaniec, mógł być sporą pomocą, kiedy źle przeszkolony mógł bardziej przeszkadzać. Znowu, kiedy wysyłaliśmy mu sprzeczne sygnały, jego zachowanie stawało się chaotyczne i trudne do przewidzenia. Projekt Black & White, był pierwszym projektem, gdzie sztuczna inteligencja uczyła się w czasie rzeczywistym w trakcie trwania gry. Do pomysłu wrócono w roku 2005 przy okazji drugiej części gry.
Obok kontynuacji Black & White w 2005 roku na półki sklepowe trafiła gra F.E.A.R autorstwa Monolith Productions. Do dziś, sztuczna inteligencja w tej grze, uznawana jest za jedną z najbardziej zaawansowanych. Przeciwnicy po za klasycznymi zachowaniami jak ukrywanie się, strzelanie do gracza, czy poszukiwanie go w przypadku utraty kontaktu wzrokowego, wykazują zachowania drużynowe. Tzn. kiedy jeden z członków zespołu zmienia pozycję, aby oskrzydlić gracza, reszta zespołu osłania go. Przeciwnicy nie atakują jedynie po najprostszej linii oporu, ale potrafią również oskrzydlać, czy zajść gracza od tyłu. Wykorzystują granaty i osłony terenowe.

Źródło zdjęcia: http://www.bit-tech.net/
Ciekawy jest tutaj fakt, że programiści Monolith nie wykorzystali żadnej rewolucyjnej techniki, a klasyczne maszyny stanów skończonych oraz algorytm A*. To co tutaj zrobiono, to niekonwencjonalne wykorzystanie metod, znanych przez wszystkich. Zasadniczo, to co może zaskakiwać, to fakt, że zamiast rozbudowanego drzewa dozwolonych stanów, przeciwnicy w F.E.A.R dysponują jedynie 3 stanami: GoTo, Animate i Use Smart Object. Dokładniejsze omówienie metod stosowanych przez Monolith może być tematem na oddzielny artykuł i… taki artykuł się pojawi. Na razie przejdziemy dalej.
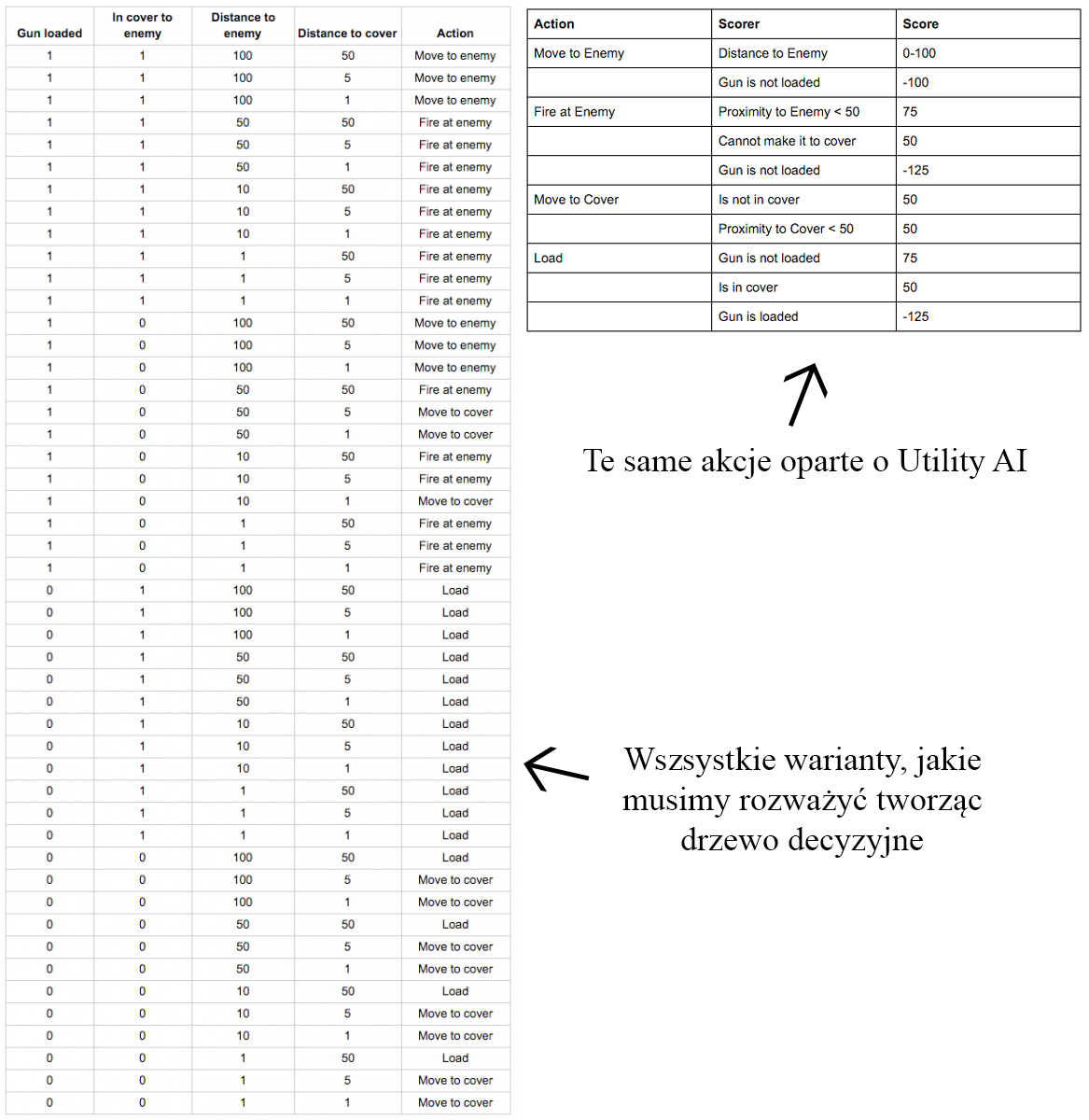
Rzućmy jeszcze okiem na przewidywanie przyszłościowe. Obecnie najczęściej stosowane metody podejmowania decyzji stosowane w grach to maszyny stanów skończonych, oraz drzewa decyzyjne. Jednak do głosu dochodzi nowa metoda, którą roboczo tłumaczę jako metodę “oceny użyteczności”. Z angielskiego, nazwa faktyczna brzmi: Utility AI. Na czym to polega? Mamy kilka możliwych akcji dostępnych dla agenta. Każda akcja podlega wycenie na podstawie kilku czynników. Agent wybiera akcję, najwyżej ocenioną w danym momencie. Nie jest to metoda jeszcze szeroko stosowana, ale zyskująca na popularności. Wynika to z dwóch rzeczy: jest dużo bardziej przejrzysta i bardziej skalowalna niż drzewa decyzyjne.
Na koniec zawitamy do listopada 2015 roku, kiedy Google zaprezentowało swoje AlphaGo. Automat podjął dwa pojedynki z zawodowymi graczami gry Go w tym z jednym z najlepszych graczy Lee Sedolem, którego pokonał w stosunku 4:1. Jest to o tyle ciekawsze od dokonań Deep Blue, że gra w Go jest dużo bardziej skomplikowana. Jednak dzięki zastosowaniu uczenia maszynowego, sieci neuronowych i metod wyszukiwania monte-carlo udało się stworzyć program, mogący rywalizować z ludźmi.
Na tym kończy się nasza podróż, przez najistotniejsze dokonania w dziedzinie sztucznej inteligencji w grach komputerowych.